Introduction
When OpenAI released GPT-Image-1 in March 2025 as a ChatGPT feature, the response was overwhelming. In just the first week, over 130 million users generated more than 700 million images—so many that OpenAI's infrastructure strained under the load. Sam Altman famously tweeted that their GPUs were "melting" from unprecedented demand. By April 23, 2025, OpenAI made the model available through the API, democratizing access for developers and businesses worldwide.
GPT-Image-1 represents a fundamental shift in image generation technology. Unlike previous models such as DALL-E 3 that relied on diffusion-based architecture, GPT-Image-1 uses a natively multimodal design integrated with the GPT-4o framework. This architectural choice delivers faster generation, better instruction adherence, and the ability to handle complex editing tasks that previously required regenerating entire images.
For content creators, product designers, marketing teams, and developers, GPT-Image-1 has become an essential tool for rapid visual creation. This guide walks you through what makes GPT-Image-1 special, how to use it effectively, how to integrate it into your workflow, and how to streamline deployment with advanced platforms like GPT Proto AI API Platform. Whether you're building your first image generation feature or scaling production systems, you'll find practical strategies for success.
Tips: OpenAI has officially launched GPT-Image-1.5, arriving just months after the original GPT-Image-1 debut in April 2025. This latest model represents a significant leap forward in the competitive AI image generation landscape, offering faster performance, better instruction following, and more reliable editing than its predecessors.
What Exactly is GPT-Image-1?
GPT-Image-1 is a natively multimodal generative transformer developed by OpenAI that understands both text and images as native inputs. It's built directly on the foundation of GPT-4o, OpenAI's multimodal flagship model, rather than being a standalone system bolted onto a language model.
The distinction matters. Traditional image generators accept text prompts and generate images in isolation. GPT-Image-1 processes both text instructions and reference images simultaneously within the same neural network architecture, enabling deeper understanding of visual context and more nuanced outputs.

The Lineage: From DALL-E to GPT-Image-1
OpenAI's image generation journey evolved through clear stages. DALL-E (2021) pioneered the text-to-image capability. DALL-E 3 (2023) refined this with better prompt adherence and safety guardrails. GPT-Image-1 represents a fundamental architectural reimagining: instead of treating image generation as a separate task, it integrates image creation into the broader multimodal GPT framework.
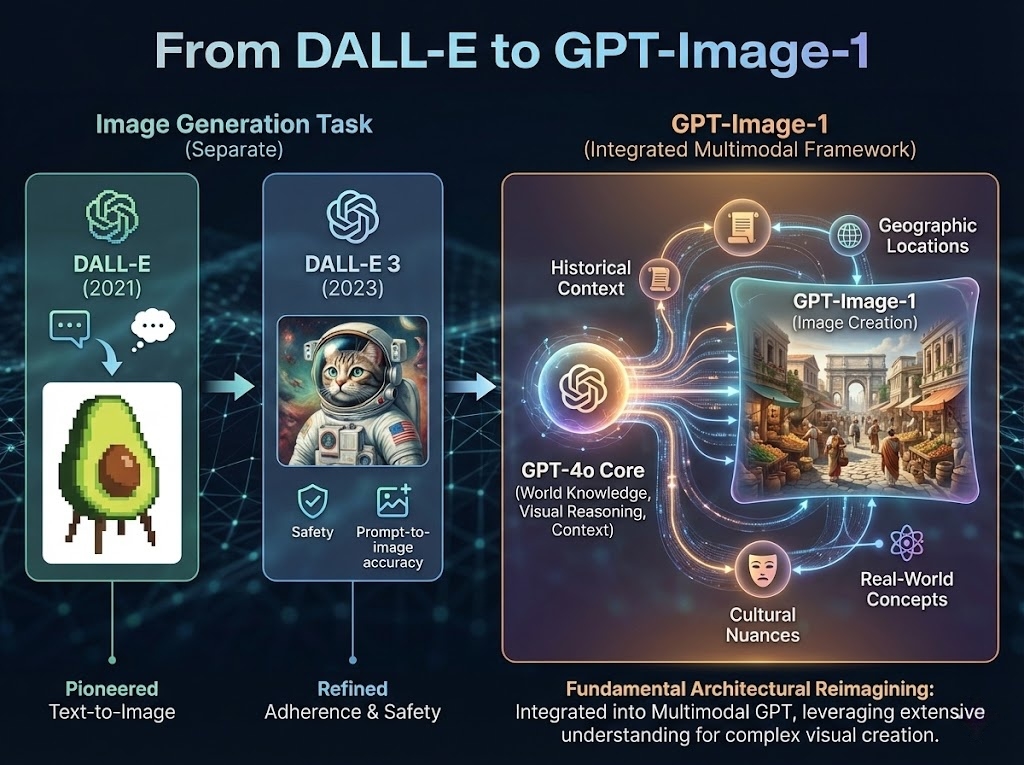
This integration means GPT-Image-1 benefits from GPT-4o's extensive world knowledge, better understanding of complex instructions, and stronger visual reasoning abilities. The model understands historical contexts, geographic locations, cultural nuances, and real-world concepts in ways previous diffusion-based models couldn't match.
Multimodal Architecture Explained
GPT-Image-1 uses an autoregressive architecture rather than diffusion. This means it generates images sequentially, predicting visual tokens one at a time, similar to how language models predict words. This approach contrasts sharply with diffusion models that iteratively refine noisy images.
The practical benefit: autoregressive models often generate faster and maintain better consistency throughout image composition. The model's visual tokens are processed through attention layers that understand spatial relationships, color harmony, and textual integration from the beginning of generation, not as an afterthought.
How GPT-Image-1 Works
Understanding how GPT-Image-1 generates images helps you craft better prompts and anticipate the model's behavior. The process unfolds in distinct stages.
The Input-Processing Stage
When you submit a text prompt, GPT-Image-1 tokenizes your natural language description. This isn't simple keyword extraction. The model deeply analyzes your prompt's semantic meaning, identifying the primary subject, compositional intent, stylistic preferences, and spatial relationships.
If you provide a reference image, the model processes it through visual token embeddings—a specialized layer that converts visual information into the same token space as text. This allows the model to understand "apply the lighting from this reference" or "maintain the style but change the subject" with remarkable precision.
The Visual Reasoning Stage
The model constructs an internal representation of what your requested image should contain. It determines:
-
Primary and secondary subjects and their spatial relationships
-
Lighting conditions and atmospheric effects (golden hour glow, harsh studio light, moonlight)
-
Artistic style and medium (photorealism, watercolor, 3D render, oil painting)
-
Color palette and composition (rule of thirds, centered focus, diagonal lines)
-
Textual elements and their placement if you've requested embedded text
This stage leverages GPT-4o's world knowledge extensively. If you request "a 1920s art deco speakeasy interior," the model understands the historical aesthetics, period-appropriate furnishings, and lighting typical of that era—without you specifying every detail.
The Image Generation Stage
Rather than progressively refining noise, GPT-Image-1 predicts image tokens directly. The model generates visual information in a sequence, maintaining consistency across the entire composition. Token predictions account for previously generated areas, ensuring that subjects don't suddenly change appearance mid-generation and that spatial layouts remain coherent.
The output supports three native resolutions: 1024×1024 (square), 1024×1536 (portrait), and 1536×1024 (landscape). Each resolution generates an image with equivalent visual information—higher pixel density in portrait/landscape modes allows for greater detail.
Core Features That Define GPT-Image-1
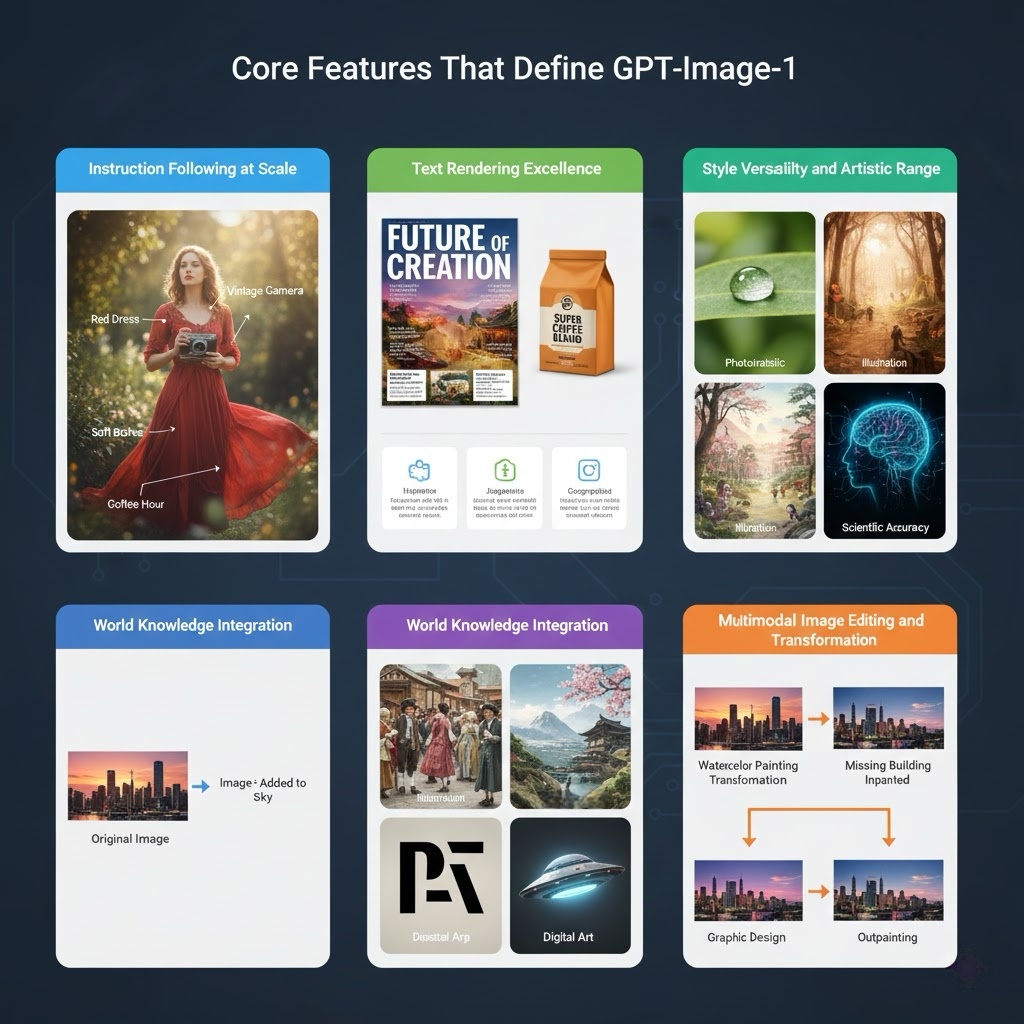
Instruction Following at Scale
GPT-Image-1's most distinctive feature is its ability to parse and execute complex, multi-faceted instructions. Previous models struggled with compound instructions like "generate a photograph of a woman in a red dress, standing in a sunlit garden, holding a vintage camera, with soft bokeh background, shot with 50mm lens, golden hour lighting, film grain effect."
GPT-Image-1 dissects this instruction into components and faithfully renders each element. More impressively, if instructions conflict (like requesting both sharp detail and motion blur), the model intelligently interprets your intent rather than averaging both effects.
Developers have tested this with hundreds of detailed prompts. The model maintains consistency even with instructions specifying multiple conditions: specific object quantities, precise color ranges, spatial positioning, and stylistic requirements simultaneously.
Text Rendering Excellence
One of the most historically difficult tasks for image generators has been rendering readable text. Early models produced illegible scribbles. DALL-E 3 improved this but remained unreliable for dense text.
GPT-Image-1 excels here. It can generate:
-
Readable signage and labels with proper letter formation
-
Magazine covers with legible headlines and article titles
-
Infographics with clear, properly positioned text
-
Posters and announcements with multiple text sizes maintaining hierarchy
-
Product packaging with functional label text
The model understands typography conventions—it knows titles should be larger than body text, that text colors should contrast with backgrounds, and that text orientation matters. For marketing materials, product mockups, and educational content, this capability alone justifies using GPT-Image-1.
Style Versatility and Artistic Range
GPT-Image-1 generates across an impressive spectrum of artistic approaches:
| Style Category |
Applications |
Typical Use |
| Photorealistic |
Product photos, architectural renderings, portraits |
E-commerce, real estate, professional portfolios |
| Illustration |
Watercolor, oil paintings, line drawings, sketches |
Publishing, editorial, fine art |
| Digital Art |
3D renders, concept art, fantasy imagery |
Gaming, entertainment, design prototypes |
| Graphic Design |
Flat design, vector-style art, minimalism, bold graphics |
Web design, branding, social media |
| Photography Styles |
Film noir, vintage stock, HDR, documentary |
Creative projects, artistic exploration |
| Anime & Animation |
Character designs, Studio Ghibli-inspired visuals |
Notably went viral upon release |
Beyond aesthetic styles, the model understands medium-specific qualities. "A charcoal sketch" produces something distinctly different from "a pencil drawing"—the model understands the inherent characteristics of each medium. This specificity makes GPT-Image-1 invaluable for creative professionals who understand how material choice affects visual outcomes.
World Knowledge Integration
GPT-Image-1 leverages GPT-4o's training across billions of text-image pairs to understand real-world contexts. This enables:
-
Historical accuracy: Generate period-appropriate scenes from any era with authentic details
-
Geographical authenticity: Create landscape scenes with regionally appropriate flora, architecture, and lighting
-
Cultural appropriateness: Generate culturally specific imagery without offensive stereotypes
-
Scientific accuracy: Create scientifically correct diagrams, anatomical illustrations, and technical visualizations
-
Contemporary knowledge: Generate images incorporating current fashion trends, modern architecture, and current events context
For professional use cases—textbooks, educational materials, documentary-style content—this world knowledge becomes a significant advantage over models trained purely on images without deep semantic understanding.
Multimodal Image Editing and Transformation
GPT-Image-1 supports four distinct editing modes beyond simple generation:
Text-to-Image Editing: Describe changes to an existing image using natural language. Rather than regenerating the entire image, GPT-Image-1 applies focused modifications, preserving unchanged areas.
Image-to-Image Transformation: Upload an image and request a transformation. The model can change artistic style, adjust composition, or reimagine the subject while maintaining elements you specify.
Inpainting: Specify a region (via bounding box or mask) for modification while the model regenerates only that area, maintaining coherence with surrounding content.
Outpainting: Expand an image beyond its original boundaries, extending compositions with contextually appropriate content.
These editing capabilities open workflows impossible with single-generation models. A designer can iterate rapidly, testing multiple variations of a single base image without starting from scratch each time.
GPT-Image-1 Pricing Structure
Token-Based Pricing
OpenAI prices GPT-Image-1 using its standard token-based system. This approach provides transparency and scales based on actual usage:
-
Text Input Tokens: $5 per 1 million tokens (your prompt text)
-
Image Input Tokens: $10 per 1 million tokens (if you provide reference images)
-
Image Output Tokens: $40 per 1 million tokens (the generated image)
In practical terms, a simple prompt (50-100 tokens) contributes negligibly to costs. Image outputs dominate pricing, varying by resolution and quality settings.
Per-Image Cost Breakdown
While token pricing provides the technical structure, understanding per-image costs helps budget planning:
| Resolution |
Standard Quality |
High Quality |
| 1024×1024 (Square) |
$0.01 |
$0.17 |
| 1024×1536 (Portrait) |
$0.02 |
$0.26 |
| 1536×1024 (Landscape) |
$0.02 |
$0.26 |
Standard quality handles most use cases: social media content, presentations, drafts, and iterations. High quality justifies its premium for final deliverables, large prints, and professional applications.
Real-World Cost Scenarios
Small Creator Budget (10-20 images/month)
-
Estimated monthly cost: $0.50-$1.00
-
Perfect for: Hobby use, experimentation, personal projects
Content Creator Workflow (100-200 images/month)
-
Mix of standard/high quality: $2-$5/month
-
Suitable for: Blog illustrations, social media content, creative exploration
E-Commerce Business (5,000 images/month)
-
Mostly standard quality with selective high-quality final outputs: $40-$60/month
-
Use cases: Product variations, lifestyle photography, catalog imagery
Enterprise Production Pipeline (50,000+ images/month)
-
Optimized mix strategy with smart quality selection: $400-$600/month
-
Applications: Large-scale content generation, continuous production workflows
Getting Started with GPT-Image-1 API
Prerequisites and Setup
To begin using GPT-Image-1 programmatically:
-
Create an OpenAI account at platform.openai.com
-
Verify your organization (required in some regions)
-
Set up billing with a valid payment method
-
Generate an API key from your account dashboard
-
Store your API key securely as an environment variable (never hardcode it in scripts)
New accounts receive $5 in free credits, sufficient for extensive experimentation—approximately 500 standard-quality square image generations.
Basic Implementation Pattern
The simplest implementation requires just a few lines of code. Here's the essential pattern using Python:
import requests
import json
api_key = "your-api-key-here"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-image-1",
"prompt": "A serene mountain landscape at sunrise, misty valleys, golden light, oil painting style",
"size": "1024x1024",
"quality": "standard",
"n": 1
}
response = requests.post(
"https://api.openai.com/v1/images/generations",
headers=headers,
json=payload
)
result = response.json()
image_url = result['data'][0]['url']
print(f"Generated image: {image_url}")
The API returns URLs to generated images, valid for 60 days. Download and store images permanently if you plan to use them beyond this window.
Prompt Engineering for Better Results
Effective prompts follow a consistent structure that provides context without overwhelming the model:
Structure: [Subject] + [Setting/Context] + [Style/Medium] + [Lighting/Mood] + [Technical Details]
Weak Prompt: "A cat"
Effective Prompt: "A fluffy orange tabby cat sitting attentively on a wooden fence post, countryside setting, overcast afternoon light, professional wildlife photography, shallow depth of field, natural colors"
Key practices:
-
Be specific about quantities: "Three apples" not "some apples"
-
Describe spatial relationships: "On the left side," "in the background," "surrounding the subject"
-
Specify lighting explicitly: Instead of vague "good lighting," describe "warm golden hour sunlight" or "cool blue moonlight"
-
Name artistic references: "In the style of Studio Ghibli" or "like a Renaissance painting" provides stronger guidance than generic "artistic"
-
Mention technical photography terms if appropriate: "Shot with 85mm lens," "cinematic depth of field," "RAW color grading"
Pro tip: Longer prompts (200-500 tokens) typically yield more detailed results than minimalist descriptions. The model excels at parsing detailed specifications and rarely ignores well-articulated instructions.
GPT-Image-1 vs. Competing Solutions
GPT-Image-1 vs. DALL-E 3
While DALL-E 3 remains functional, GPT-Image-1 supersedes it across nearly all dimensions:
| Dimension |
DALL-E 3 |
GPT-Image-1 |
Winner |
| Architecture |
Diffusion-based |
Autoregressive/Multimodal |
GPT-Image-1 |
| Text Rendering |
Limited, unreliable |
Excellent, production-ready |
GPT-Image-1 |
| Generation Speed |
Moderate (20-30s typical) |
Faster (10-20s typical) |
GPT-Image-1 |
| Editing Precision |
Poor (requires regeneration) |
Excellent (targeted edits) |
GPT-Image-1 |
| Instruction Following |
Good |
Superior |
GPT-Image-1 |
| World Knowledge Integration |
Limited |
Extensive (GPT-4o based) |
GPT-Image-1 |
| API Pricing |
$0.02-$0.20 per image |
$0.01-$0.17 per image |
GPT-Image-1 |
For new projects, GPT-Image-1 is the recommended choice. DALL-E 3 remains available for legacy applications or specific aesthetic requirements, but development focus has shifted entirely to GPT-Image-1.
GPT-Image-1 vs. Midjourney
Midjourney excels in artistic aesthetics and community-driven exploration. It produces images with a distinctive, often ethereal quality that appeals to digital artists and creative professionals. Its Discord-based interface fosters an active creator community.
GPT-Image-1 targets different priorities: API integration, production reliability, instruction adherence, and enterprise deployment. It's deterministic (consistent results from identical prompts), includes robust safety guardrails, and integrates seamlessly into applications.
Choose Midjourney if: You prioritize artistic flexibility, community exploration, and aesthetic variety.
Choose GPT-Image-1 if: You need programmatic integration, instruction-following precision, production reliability, and text rendering.
GPT-Image-1 vs. Google's Imagen 3 and Nano Banana Pro
Google released Imagen 3, a diffusion-based model emphasizing photorealistic outputs and nuanced lighting control. It's available through Google's Gemini and Vertex AI platforms.
Nano Banana Pro, Google's latest iteration, combines diffusion-based generation with post-production editing features, offering competitive iteration capabilities.
OpenAI's response: GPT-Image-1's multimodal foundation provides advantages in semantic understanding and world knowledge integration that pure diffusion models struggle to match. Its API availability across platforms (OpenAI, Azure, and third-party AI API providers) exceeds Imagen's more limited distribution.
Tips: For more differences please read GPT Image vs Nano Banana.
GPT-Image-1's Limitations and Known Considerations
Current Technical Limitations
GPT-Image-1 performs best on single subjects and clear composition. Complex scenes with many objects or multiple interacting subjects sometimes show inconsistencies. The model remains challenged by:
-
Multiple human faces: Generating scenes with multiple people can produce inconsistent facial structures
-
Complex hand positions: Hands remain notoriously difficult (a challenge for all image generation models)
-
Small, detailed text: While text rendering is excellent, extremely small text in dense layouts may require iteration
-
Extremely specific brand logos: The model avoids reproducing copyrighted content precisely
Known Color and Style Biases
Analysis of GPT-Image-1 outputs reveals subtle characteristics:
-
A slight warm color bias in many outputs (affects some landscape and portrait photography)
-
Premature cropping of composition in some configurations (generally addressed in GPT-Image-1.5)
-
Occasional challenges with specific art styles where few training examples exist
These limitations aren't failures but rather areas requiring prompt adjustment or iterative refinement. Most production workflows involve 2-3 iterations anyway; understanding these biases helps you prompt more effectively.
Advanced GPT-Image-1 Integration with GPT Proto
For developers and businesses looking to integrate cutting-edge AI capabilities, GPT Proto offers a comprehensive solution that goes beyond image generation. This powerful platform provides access to the latest AI models, including support for ChatGPT 4.1 variants such as gpt-4.1, gpt-4.1-nano, and gpt-4.1-mini.
GPT Proto serves as a unified AI API platform that connects you with the world's most advanced AI models, all in one convenient location. Instead of managing multiple API providers, you can access GPT, Claude, Gemini, Midjourney, and other leading models through a single, pay-as-you-go service.
Built by developers for developers, the platform features clean, well-documented APIs that make integration straightforward, whether you're building applications or testing prototypes. With globally distributed and highly optimized API endpoints, your applications maintain fast response times for generating text, images, music, or video content.
The platform continuously adds the latest models like Grok, Runway, and Kling, ensuring you stay ahead without switching platforms. As an AI Model aggregator, GPT Proto welcomes feedback from independent developers and teams to shape their roadmap and build a community that pushes the boundaries of AI possibilities.
Conclusion
GPT-Image-1 represents a paradigm shift in AI-powered image generation, combining advanced multimodal architecture with enterprise-grade reliability to deliver photorealistic and artistically diverse outputs at scale. From its superior text rendering and instruction-following capabilities to flexible pricing and seamless API integration, GPT-Image-1 empowers content creators, businesses, and developers to streamline visual creation workflows while maintaining production consistency. Whether you're generating marketing assets, product mockups, educational content, or exploring creative possibilities, GPT-Image-1's native multimodal design, world knowledge integration, and iterative editing capabilities establish it as the definitive choice for professionals seeking precision, scalability, and rapid visual deployment. For teams seeking a unified AI platform that consolidates access to GPT-Image-1 alongside other leading models, GPT Proto AI API offers a comprehensive solution with optimized API endpoints, simplified integration, and cost-effective deployment—enabling developers to scale image generation workflows without managing multiple service providers, making it an invaluable infrastructure choice for enterprises building next-generation AI applications in 2026 and beyond.




